
本篇blog,依据于笔记CS224n_winter2023.Homework基于CS224n_winter2025.
选择nlp作为我入门的第一个stanford课程,是因为如今transform大行其道,他在处理长时许任务时,表现非凡。让我们开始吧!!!
如何表示一个单词
独热向量
也许表示单词最简单的方式是将它们视为独立、不相关的实体。你或许可以把这看作一个集合。
{\{ …, tea, …, coffee, …, antiridate }\}- 基本概念:单词类型(type)是词汇表中的独立元素(抽象概念),单词实例(token)是类型在具体语境中的出现(如句子中的 “tea”)。
- 独热向量表示:将每个单词类型表示为独热向量(标准基向量),例如:
v_{\text{tea}} = \begin{bmatrix}
0 \\
0 \\
1 \\
\vdots \\
0
\end{bmatrix}, \quad
v_{\text{coffee}} = \begin{bmatrix}
\vdots \\
0 \\
0 \\
1 \\
\vdots
\end{bmatrix} \quad (1)- 缺点:独热向量仅能区分不同单词(如点积、L1/L2 距离均为 0,所有单词同等 “不同”),无法编码单词间的相似性或其他关联,且不含字符级信息(仅通过字符序列是否完全一致判断向量是否相同)。
Distributional semantics
nlp领域有一句名言:You shall know a word by the company it keeps.
举一个例子,我们选择tea为中心词。

较小的窗口(如上面标记为1的单词语窗)似乎编码了句法属性。例如,名词往往出现在“the”或“is”的紧挨着的位置。复数名词不会出现在“a”的紧旁边。较大的窗口则倾向于编码更多语义属性(在极端情况下,还会涉及类似主题的属性)。注意,“poured”(倾倒)或“delicious”(美味的)可能离“tea”(茶)较远,但仍然相关。对于大型文档(数千个单词)而言,文档级别的窗口直观上通过词语所出现的文档类型(体育、法律、医学等)来表示这些词语。
量化单词之间的紧密程度
那么我们该怎么量化单之间的紧密程度呢?这里我们给出两个方法,共现矩阵(co-occurrence matrices),与Skipgram模型。
Co-occurrence matrices
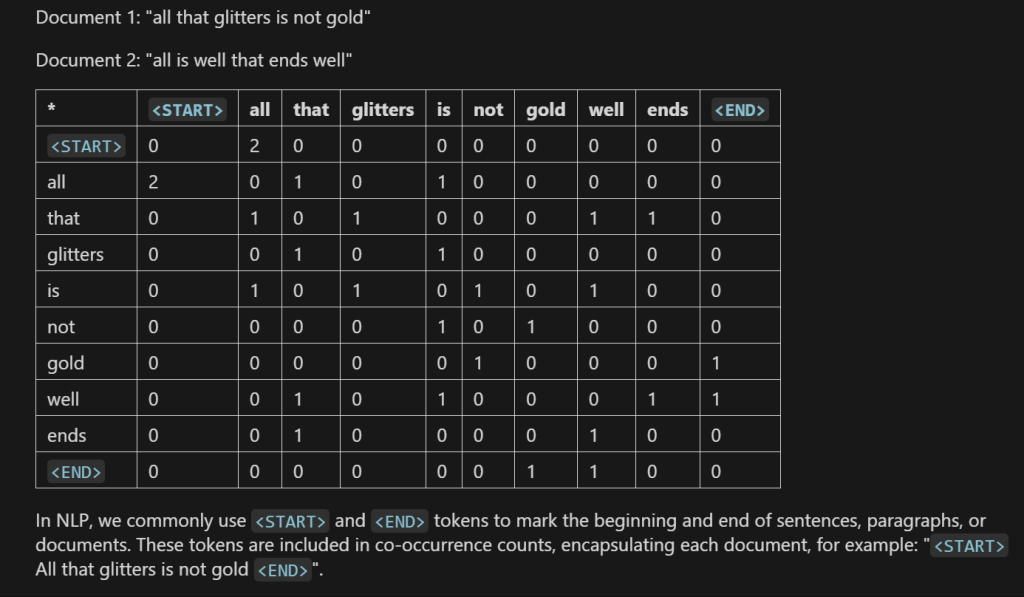
共现矩阵是通过统计 “单词与上下文单词共同出现次数” 构建的高维稀疏矩阵,具体步骤为:
- 确定词汇表:先定义模型覆盖的有限词汇表V(包含所有待处理的单词类型)
- 初始化矩阵:创建一个维度为 |V|×|V| 的零矩阵,矩阵的行和列均对应词汇表V中的单词;
- 统计共现次数:遍历所有文档,对每个文档中的每个中心词wc,将该词上下文窗口内所有其他单词wo的计数,累加到矩阵中 “wc行、wo'列” 的位置(例如,若 “tea” 的上下文出现 “hot”,则矩阵中(tea, hot)的元素值加 1);
- 归一化处理:对矩阵的每一行(对应一个中心词)进行归一化(如除以该行所有元素之和),使每行元素转化为 “中心词与其他单词的共现频率”,最终得到共现矩阵。此时,矩阵的每一行向量x(如x{tea})即为单词wc (tea)的向量表示。
Skipgram word
word2vec模型将固定词汇表中的每个单词表示为一个低维(远小于词汇表大小)向量。它通过一个简单的函数来学习每个单词向量的值,该函数基于(通常较短,2-4个单词的)语境中单词的分布进行预测。我们在这里要介绍的模型被称Skipgram word2vec算法。
一、模型基础设定:词汇表与核心变量
- 有限词汇表 V:模型首先定义一个有限的词汇表 V,所有待处理的单词(如 “tea”“coffee”“Zuko” 等)均来自该词汇表,这是模型的基础范围界定,避免处理无边界的语言数据。
- 随机变量 C 与 O:
- 中心词 C:随机变量 C 的取值范围是词汇表 V,代表在文本序列中被选为 “中心” 的单词,是模型分析的核心对象
- 上下文词 O:随机变量 O 的取值范围同样是 V,代表出现在中心词 C 上下文范围内的单词(“outside word”),例如若 “tea” 为中心词,上下文窗口大小为 2,则 “the”“makes” 可能成为 O 的具体取值。
- 具体取值 c 与 o:当需要指代随机变量的具体实例时,用 c 表示 C 的某个具体值(如 c=tea),用 o 表示 O 的某个具体值(如 o=the),用于后续概率计算。
- 参数矩阵 U 与 V:
- 维度与含义:矩阵U∈R|v|×d (上下文词向量矩阵) 和V∈R|v|×d (中心词向量矩阵)是模型的核心参数,其中|V|是词汇表中单词的总数,d 是单词向量的维度(通常为几十到几百,远小于|V|,实现 “低维表示” 的目标)。
参数矩阵U,V就是我们实现的word2vec,但是具体怎么得到???

二、概率公式:softmax 函数与条件概率建模
首先,我们需要定义两个wordvec的相关性与损失函数, 然后利用梯度下降的方式,优化U,V参数矩阵。
模型通过以下公式定义 “给定中心词 c 时,上下文词为 o” 的条件概率:
p_{U,V}(o|c) = \frac{\exp u_o^\top v_c}{\sum_{w \in \mathcal{V}} \exp u_w^\top v_c} 该公式的本质是softmax 函数,其核心作用是将 “单词向量相似度” 转化为 “概率分布”,具体拆解如下:
- 分子:相似性得分的指数化:
- 向量内积:uo是上下文词 o 在 U 中的对应行(o 的上下文向量)。vc是中心词 c 在 V 中的对应行(c 的中心向量). 内积是用于衡量 o 与 c 的 “关联紧密程度”—— 内积值越大,说明两个单词在语义或句法上的关联越近(例如 c=tea、o=coffee 时,内积可能比 c=tea、o=Zuko 时更大)。
- 指数函数:对向量内积结果取指数,一方面将可能为负的内积值转化为非负值(符合概率的非负性要求),另一方面会放大内积值的差异 —— 内积越大,指数化后的值增长越快,使关联紧密的单词在后续概率计算中更具优势。
- 分母:全词汇表的归一化项:
- 求和项:遍历词汇表 V 中的所有单词 w,计算每个 w 的上下文向量uw与中心词 c 的中心向量vc 的内积,并对结果取指数后求和。这一求和项被称为 “归一化因子” 或 “分区函数(Partition Function)”。
- 归一化:通过分母的求和,将分子中单个单词 o 的指数化得分,除以所有单词的指数化得分之和,使最终结果p{U, V}(o | c)落在 [0,1] 区间内,且所有 “给定 c 时不同 o” 的概率之和为 1,满足概率分布的基本性质。
三、 定义损失函数
我们通过学习来最小化与真实分布P*(O | C)相关的交叉熵损失目标:
min_{U, V} \mathbb{E}_{o, c}\left[-log p_{U, V}(o | c)\right] 其本质是让模型预测的 “给定中心词c时上下文词o的概率分布p{U, V}(o | c),尽可能接近真实语言数据中 “c与o共现的分布P*(O | C),
损失函数具体应用:设文档集D(每个文档为单词序列w1(d)......wm(d)),窗口大小k,则对于c=wi(d), o=wi-k(d) ....wi-1(d) , wi+1(d),..... wi+k(d)目标函数转化为对所有文档、所有单词、所有窗口内上下文词的负对数概率。
L(U,V) = \sum_{d \in D} \sum_{i=1}^{m} \sum_{j=1}^{k} -\log p_{U,V}(w_{i-j}^{(d)} \mid w_i^{(d)})
四、梯度下降实现
梯度下降的目标: 优化参数矩阵U,V ,对应求导对象vc,uo
梯度下降方法:
- 初始参数:U ,V 从均值为 0、方差为 0.001 的正态分布随机采样;
- 迭代更新:通过梯度下降调整参数,第i+1次迭代公式为
\boldsymbol{U}^{(i+1)}=\boldsymbol{U}^{(i)}-\alpha\nabla_{\boldsymbol{U}}L(\boldsymbol{U}^{(i)},\boldsymbol{V}^{(i)})
随机梯度优化:由于计算全量损失成本高,故采样少量文档近似计算损失(不计算所有的L(U,V)每次选择一部分) ,用近似梯度更新参数,降低计算开销。
\hat{L}(U, V)=\sum_{d_{1}, ..., d_{\ell}} \sum_{i=1}^{m} \sum_{j=1}^{k}-log p_{U, V}\left(w_{i-j}^{(d)} | w_{i}^{(d)}\right)接下来进行梯度推导:
我们将写出损失函数对参数vc的偏梯度。(uo同理)
\nabla_{v_{c}} \hat{L}(U, V)=\sum_{d \in D} \sum_{i=1}^{m} \sum_{j=1}^{k}-\nabla_{v_{c}} log p_{U, V}\left(w_{i-j}^{(d)} | w_{i}^{(d)}\right)为了简化符号,我们将wi-jd再次记为o,将wid记为c。
\begin{array} {rlrl}{\nabla _{v_{c}} log p_{U, V}(o | c) }&{=\nabla _{v_{c}} log \frac {exp u_{o}^{\top } v_{c}}{\sum _{i=1}^{n} u_{w}^{\top } v_{c}} }&{ (10) }\\ & =\underbrace {\nabla _{v_{c}} log exp u_{o}^{\top } v_{c}}_{PartA }-\underbrace {\nabla _{c} log \sum_{i=1}^{n} exp u_{w}^{\top } v_{c}}_{PartB } & (11) \end{array}A部分。我们先对A部分求导,因为它更简单。
\begin{aligned} \nabla_{v_{c}} log exp u_{o}^{\top} v_{c} & =\nabla_{v_{c}} u_{o}^{\top} v_{c} & & inverse operations (12) \\ & =u_{o} & & why? & (13) \end{aligned}12->13是怎么来的 ?






B部分。现在让我们对B部分进行微分。
\begin{aligned} -\nabla_{v_{c}} log \sum_{w=1}^{n} exp u_{w}^{\top} v_{c} & =\frac{1}{\sum_{w=1}^{n} exp u_{w}^{\top} v_{c}} \nabla_{v_{c}} \sum_{x=1}^{n} exp u_{x}^{\top} v_{c} & & derivative of log; chain rule \\ & =\frac{1}{\sum_{w=1}^{n} exp u_{w}^{\top} v_{c}} \sum_{x=1}^{n} \nabla_{v_{c}} exp u_{x}^{\top} v_{c} & & linearity of derivative \\ & =\frac{1}{\sum_{w=1}^{n} exp u_{w}^{\top} v_{c}} \sum_{x=1}^{n} exp \left(u_{x}^{\top} v_{c}\right) \nabla_{v_{c}} u_{w}^{\top} v_{c} & & derivative of exponential; chain rule \\ & =\frac{1}{\sum_{w=1}^{n} exp u_{w}^{\top} v_{c}} \sum_{x=1}^{n} exp \left(u_{x}^{\top} v_{c}\right) u_{w} & & derivative of dot product \end{aligned}现在我们将利用这一点来获得一些见解。让我们把A部分和B部分结合起来,做一点代数运算:
\begin{aligned} u_{o}-\underbrace{\frac{1}{\sum_{w=1}^{n} exp u_{w}^{\top} v_{c}}}_{pull this under the sum } \sum_{x=1}^{n} exp \left(u_{x}^{\top} v_{c}\right) u_{w} & =u_{o}-\underbrace{\sum_{x=1}^{n} \frac{exp \left(u_{x}^{\top} v_{c}\right)}{\sum_{w=1}^{n} exp u_{w}^{\top} v_{c}}}_{This is p_{U, V}(x | c)} u_{w} \\ & =u_{o}-\underbrace{\sum_{x=1}^{n} p_{U, V}(x | c)}_{This is an expectation } u_{w} \\ & =u_{o}-\mathbb{E}\left[u_{w}\right] \\ & = "observed" - "expected", \end{aligned}中心词向量vc的更新方向,是让它 “更贴近真实观测到的上下文词向量uo,而远离模型原本期望的向量Euw
五、负采样
我们注意到,在计算梯度的时候,需要计算 softmax 概率的分母,它需要遍历词汇表V中的每一个单词w


SGNS 的创新就在于 “用随机采样替代全量压制”,在降低成本的同时保留核心学习逻辑。



这样用 “随机少量压制” 替代 “全量压制”,成本骤降且效果近似
Comments 1 条评论
哇🤩,jygg 好棒!